Wireshark can read in a hex dump and write the data described into a temporary libpcap capture file. It can read hex dumps with multiple packets in them, and build a capture file of multiple packets. It is also capable of generating dummy Ethernet, IP and UDP, TCP, or SCTP headers, in order to build fully processable packet dumps from hexdumps of application-level data only. Alternatively, a Dummy PDU header can be added to specify a dissector the data should be passed to initially.
Two methods for converting the input are supported:
Wireshark understands many different hex dump formats. The native format
that Wireshark displays in the Packet Bytes pane, copies to the clipboard,
prints, and saves is that generated by od -Ax -tx1 -v or hexdump -X -v.
That is, each line begins with an offset describing the position in the packet,
each byte is individually displayed, with spaces separating the bytes from
each other, and repeated or all NUL ('\0') lines are not omitted. Hex digits
can be upper or lowercase. Wireshark can handle other hex dump formats, some
of which can be automatically detected and some of which require enabling
options to properly recognize.
Offsets are followed by one or more spaces or tabs separating them from the
bytes. Offsets optionally can be followed by a single colon after the digits.
Offsets can be between 3 and 8 digits; hexadecimal base (radix) is assumed by
default, but they can also be in octal or decimal. If offsets are in hex,
they can be preceded by 0x or 0X. Each packet must begin with offset zero,
and an offset zero indicates the beginning of a new packet. Offset values must
be correct; an unexpected value causes the current packet to be aborted and the
next packet start awaited. There is also a single packet mode with no offsets.
There is no limit on the width or number of bytes per line, but lines with only hex bytes without a leading offset are ignored (i.e., line breaks should not be inserted in long lines that wrap.) Bytes must be in hex; unlike with offsets, other bases such as octal, decimal, or binary are unsupported. Byte groups of two to four bytes are also supported. By default byte groups are assumed to be in network (big-endian) byte order; the “Little-endian” option can be used to support little-endian byte order.
Packets may be preceded by a direction indicator ('I' or 'O') and/or a timestamp if indicated. If both are present, the direction indicator precedes the timestamp. The format of the timestamps must be specified. If no timestamp is parsed, in the case of the first packet the current system time is used, while subsequent packets are written with timestamps one microsecond later than that of the previous packet.
Other text in the input data is ignored. Any text before the offset is ignored, including email forwarding characters '>'. Any text on a line after the bytes is ignored, e.g. an ASCII character dump (but enable the “ASCII identification” option to ensure that hex digits in the character dump are ignored if there is no delimiter between the hex dump and the ASCII character translation). Any line where the first non-whitespace character is a '#' will be ignored as a comment. Some hex dump utilities use a line containing a single '*' to indicate omitted lines, either duplicating the previous line or entirely consisting of NUL ('\0') bytes; this is not supported. Any lines of text between the bytestring lines are considered preamble; the beginning of the preamble is scanned for the direction indicator and timestamp as mentioned above and otherwise ignored.
Here is a sample dump that can be imported, including optional directional indicator and timestamp:
I 2019-05-14T19:04:57Z 000000 00 e0 1e a7 05 6f 00 10 ........ 000008 5a a0 b9 12 08 00 46 00 ........ 000010 03 68 00 00 00 00 0a 2e ........ 000018 ee 33 0f 19 08 7f 0f 19 ........ 000020 03 80 94 04 00 00 10 01 ........ 000028 16 a2 0a 00 03 50 00 0c ........ 000030 01 01 0f 19 03 80 11 01 ........
Wireshark is also capable of scanning the input using a custom Perl regular
expression as specified by GLib’s GRegex here.
Using a regex capturing a single packet in the given file
Wireshark will search the given file from start to the second to last character
(the last character has to be \n and is ignored)
for non-overlapping (and non-empty) strings matching the given regex and then
identify the fields to import using named capturing subgroups. Using provided
format information for each field they are then decoded and translated into a
standard libpcap file retaining packet order.
Note that each named capturing subgroup has to match exactly once a packet, but they may be present multiple times in the regex.
For example, the following dump:
> 0:00:00.265620 a130368b000000080060 > 0:00:00.280836 a1216c8b00000000000089086b0b82020407 < 0:00:00.295459 a2010800000000000000000800000000 > 0:00:00.296982 a1303c8b00000008007088286b0bc1ffcbf0f9ff > 0:00:00.305644 a121718b0000000000008ba86a0b8008 < 0:00:00.319061 a2010900000000000000001000600000 > 0:00:00.330937 a130428b00000008007589186b0bb9ffd9f0fdfa3eb4295e99f3aaffd2f005 > 0:00:00.356037 a121788b0000000000008a18
could be imported using these settings:
regex: ^(?<dir>[<>])\s(?<time>\d+:\d\d:\d\d.\d+)\s(?<data>[0-9a-fA-F]+)$ timestamp: %H:%M:%S.%f dir: in: < out: > encoding: HEX
Caution has to be applied when discarding the anchors ^ and $, as the input
is searched, not parsed, meaning even most incorrect regexes will produce valid
looking results when not anchored (however, anchors are not guaranteed to prevent
this). It is generally recommended to sanity check any files created using
this conversion.
Supported fields:
-
data: Actual captured frame data
The only mandatory field. This should match the encoded binary data captured and is used as the actual frame data to import.
-
time: timestamp for the packet
The captured field will be parsed according to the given timestamp format into a timestamp.
If no timestamp is present an arbitrary counter will count up seconds and nanoseconds by one each packet.
-
dir: the direction the packet was sent over the wire
The captured field is expected to be one character in length, any remaining characters are ignored (e.g., given "Input" only the 'I' is looked at). This character is compared to lists of characters corresponding to inbound and outbound and the packet is assigned the corresponding direction. If neither list yields a match, the direction is set to unknown.
If this field is not specified the entire file has no directional information.
-
seqno: an ID for this packet
Each packet can be assigned an arbitrary ID that can used as field by Wireshark. This field is assumed to be a positive integer base 10. This field can e.g. be used to reorder out of order captures after the import.
If this field is not given, no IDs will be present in the resulting file.
This dialog box lets you select a text file, containing a hex dump of packet data, to be imported and set import parameters.
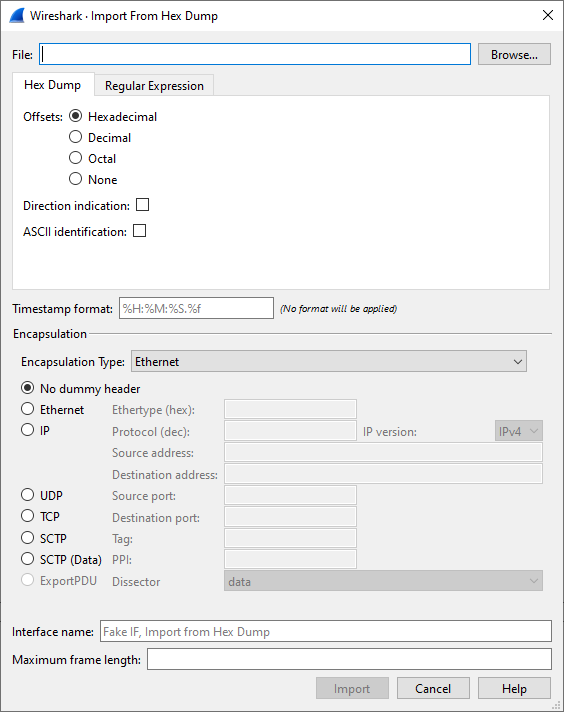
Specific controls of this import dialog are split in three sections:
- File Source
- Determine which input file has to be imported
- Input Format
- Determine how the input file has to be interpreted.
- Encapsulation
- Determine how the data is to be encapsulated.
- Filename / Browse
- Enter the name of the text file to import. You can use Browse to browse for a file.
This section is split in the two alternatives for input conversion, accessible in the two Tabs "Hex Dump" and "Regular Expression"
In addition to the conversion mode specific inputs, there are also common parameters, currently only the timestamp format.
- Offsets
- Select the radix of the offsets given in the text file to import. This is usually hexadecimal, but decimal and octal are also supported. Select None when only the bytes are present. These will be imported as a single packet.
- Direction indication
- Tick this box if the text file to import has direction indicators before each frame. These are on a separate line before each frame and start with either I or i for input and O or o for output.
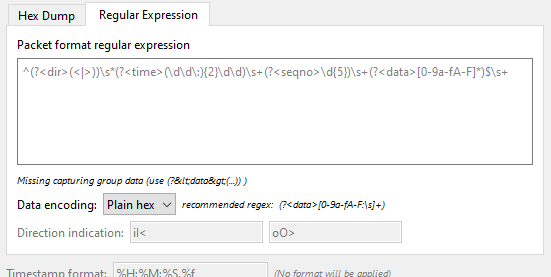
- Packet format regular expression
-
This is the regex used for searching packets and metadata inside the input file.
Named capturing subgroups are used to find the individual fields. Anchors
^and$are set to match directly before and after newlines\nor\r\n. See GRegex for a full documentation. - Data encoding
-
The Encoding used for the binary data. Supported encodings are plain-hexadecimal, -octal, -binary and base64. Plain here means no additional characters are present in the data field beyond whitespaces, which are ignored. Any unexpected characters abort the import process.
Ignored whitespaces are
\r,\n,\t,\v, ` ` and only for hex:, only for base64=.Any incomplete bytes at the field’s end are assumed to be padding to fill the last complete byte. These bits should be zero, however, this is not checked.
- Direction indication
-
The lists of characters indicating incoming vs. outgoing packets. These fields
are only available when the regex contains a
(?<dir>…)group.
- Timestamp Format
-
This is the format specifier used to parse the timestamps in the text file to import. It uses the same format as
strptime(3)with the addition of%ffor zero padded fractions of seconds. The precision of%fis determined from its length. The most common fields are%H,%Mand%Sfor hours, minutes and seconds. The straightforward HH:MM:SS format is covered by %T. For a full definition of the syntax look forstrptime(3),In Regex mode this field is only available when a
(?<time>…)group is present.In Hex Dump mode if there are no timestamps in the text file to import, leave this field empty and timestamps will be generated based on the time of import.
- Encapsulation type
- Here you can select which type of frames you are importing. This all depends on from what type of medium the dump to import was taken. It lists all types that Wireshark understands, so as to pass the capture file contents to the right dissector.
- Dummy header
- When Ethernet encapsulation is selected you have to option to prepend dummy headers to the frames to import. These headers can provide artificial Ethernet, IP, UDP, TCP or SCTP headers or SCTP data chunks. When selecting a type of dummy header, the applicable entries are enabled, others are greyed out and default values are used. When the Wireshark Upper PDU export encapsulation is selected the option ExportPDU becomes available. This allows you to select the name of the dissector these frames are to be directed to.
- Maximum frame length
- You may not be interested in the full frames from the text file, just the first part. Here you can define how much data from the start of the frame you want to import. If you leave this open the maximum is set to 256kiB.
Once all input and import parameters are setup click to start the import. If your current data wasn’t saved before you will be asked to save it first.
If the import button doesn’t unlock, make sure all encapsulation parameters are in the expected range and all unlocked fields are populated when using regex mode (the placeholder text is not used as default).
When completed there will be a new capture file loaded with the frames imported from the text file.